Here is the paper
PAST stands for Per-Address Spanning Tree routing algorithm which is the core idea behind the paper. Much of the introduction is similar to SEATTLE.
Pure Ethernet
Pros:
1) Self-configuration (plug-and-play)
2) Allows host mobility without hassles.
Cons:
1) Not scalable (Flooding based learning does not scale for more than 1000 hosts and also the MAC table becomes huge because each switch has to know how to divert traffic to all hosts and MAC addresses don't aggregate). We can limit broadcasts by using VLANs but they are limited (4094).
2) Spanning trees limits the available bandwidth by removing links to avoid forwarding loops.
IP
Pros:
1) Allows ECMP forwarding (limited to layer 3 networks currently). More efficient use of available bandwidth.
2) IP addresses are aggregatable and hence scalable.
Cons:
1) Difficult to configure and manage (router config, DHCP server config --> error prone)
2) Host mobility is an issue. Live Migration is needed for fault tolerance and to achieve high host utilization.
Ethernet + IP
Group Ethernet LANs via IP (run OSPF among IP routers). Layer 3 routers allow for ECMP routing and provide scalability.
Cons:
Subnetting limits host mobility to within a single LAN (subnet). Scalability becomes an issue as tenants grow. Subnetting wastes IP addresses and increases configuration overhead both of routers and DHCP servers.
Problem statement
We want ease and flexibility of Ethernet and the scalability and performance of IP while using inexpensive commodity hardware (using proprietary hardware is harder to deploy and loses the advantage of economies of scale) and should work with arbitrary topologies.
PAST relies solely on destination MAC and VLAN tags to forward the packets. So, it can use the larger MAC tables (SRAM) instead of TCAMs (higher area and power per entry than SRAM).
The paper provides a good overview of Trident switch chip and a useful table on table sizes of some of the available commercial 10Gbps switches:
 http://www.intel.com/content/www/us/en/switch-silicon/ethernet-switch-fm6000-series.html
http://www.intel.com/content/www/us/en/switch-silicon/ethernet-switch-fm6000-series.html
IntelFM6000 support 64K IPv4 routes as well.
Lack of information about switch internals makes it difficult for networking researchers to consider constraints of real hardware. This paper fills this gap (for Trident switch chip).
L2 table performs an exact match lookup on VLAN ID and dest MAC address. This table is much larger compared to TCAM tables. Output of the table is either an output port or a group.
TCAMs can wildcard match on most packet header fields. Rewrite TCAM supports output actions that modify packet headers. Forwarding TCAM is used to choose an output port or group. Trident can support 1K ECMP groups each with maximum 4 outport ports in the ECMP Group Table.
Switches contain a control plane processor that is responsible for programming the switch chip, listening to controller messages and participating in control plane protocols like spanning tree, OSPF etc.
IBM RackSwitch G8264 has unique capability to install Openflow rules that exact match on only dest MAC and VLAN ID in L2 table. The switch can install 700-1600 rules/s and each rule installation takes 2-12ms. Each time a packet matches no rule it is sent to the controller. The limit on this feature is 200 packets/s. Therefore reactive forwarding will not provide acceptable performance.
Given the small size of TCAMs any routing mechanism that requires the flexibility of a TCAM must aggregate routes. The paper argues that given the large size of L2 tables we can fit one entry per routable address in every switch. I don't believe this argument at all. Portland started out with the same argument and basically said that lets bring the benefits of aggregation to MAC addresses. But by doing so you again limit host placement (and in Portland's case topology also). To get around this, Layer 2 and 3 schemes make use of indirection to separate location and application addresses which leads to familiar set of inefficiencies.
SPAIN and TRILL are not able to exploit the advantages of multiple paths in topologies like Fat-Tree, Jellyfish because STP constructs a single tree to forward packets along to avoid forwarding loops.
TRILL runs IS-IS to build shortest path routes between switches but it uses broadcast for address resolution, limiting its scalability.
Multipath routing and Valiant load balancing are used to fully exploit available bandwidth in a network.
If there are multiple shortest paths between two hosts we can use ECMP to increase path diversity, avoid hotspots and flow collisions. But ECMP is applicable in architectures which find shortest path like IP routing and TRILL (IS-IS).
VLB forwards traffic minimally to a random switch after which the traffic follows minimal path to its destination.
Core idea
Many possible spanning trees can be built for an address if the topologies have high path diversity. If we make individual per-address trees as disjoint as possible we can improve aggregate network utilization.
Baseline: Destination-rooted shortest path trees.
Build a BFS spanning tree for every address in the network. This spanning tree is rooted at the destination host, so provides minimum hop-count path from any point in the network to that destination. No links are ever disabled in the topology. Every switch forwards the traffic to the host via the path calculated using STP. Forward and reverse paths can be asymmetric (since STP is calculated for each host).
Three variants
PAST-R
Pick a uniformly random next hop in BFS. Intuitively we are spreading the traffic across all the links since each destination will have a random spanning tree.
PAST-W
Use weighted randomization in BFS: Weigh the next hop selection by considering how many children next hop-switch has.
Above two variants are similar to ECMP. Unlike ECMP which enables load balancing at per-flow PAST enables load balancing on per-destination granularity.
NM-PAST
This is similar to VLB and achieves high performance under adversarial workloads. Select a random intermediate switch i and use it as the root for the BFS spanning tree for each host h. The switches along the path in the tree from h to i are then updated to route traffic towards h and not i, making h the sink of the tree.
Evaluations found no significant difference between PAST-R and PAST-W. NM-PAST performs better than ECMP and VLB.
Implementation
PAST uses the Openflow controller-dumb switch architecture. All switches forward the ARP messages to the controller. The controller sends back ARP replies. Ditto for DHCP. Switches run LLDP, so the controller knows the entire topology. PAST is topology independent
What happens when?
1) A host joins/migrates: Migrated host sends a gratuitous ARP which is forwarded to controller. The controller calculates the new tree for the host and updates the rules on the switches.
2) A link/switch fails: All hell breaks loose. We need to recompute all affected trees (if the switch is in the core layer this can be very costly). Biggest drawback of the paper. The paper says the algorithm can compute trees for all hosts in a network with 8,000 hosts in 300ms and 100,000 hosts in 40 seconds. Installation of a single rule on the switch takes 12ms. They say it takes up to a minute for them to recover from a single failure.
Drawbacks
1) The authors say their switch does not need special hardware but they depend on using the IBM G8264 switches which is the only switch that currently supports installing Openflow rules in the Ethernet forwarding tables.
2) Installing a recomputed tree can lead to routing loops. This can be prevented by removing rules corresponding to that tree from the switches first and then use barrier command to make sure they are removed before installing new tree rules. Wastes time.
3) PAST requires one Ethernet table entry per routable address, so the scalability of the architecture is limited to the Ethernet table size (around 100K max). The paper hopes that PAST will scale well in future networks because it uses SRAM-based Ethernet tables.
SPAIN another paper similar to PAST requires a switch to store all possible (VLAN, destination MAC) pairs hence limiting the scalability of these approaches. The paper says that the switches resort to flooding in case of table overflows which is not acceptable in a big data center.
PAST stands for Per-Address Spanning Tree routing algorithm which is the core idea behind the paper. Much of the introduction is similar to SEATTLE.
Pure Ethernet
Pros:
1) Self-configuration (plug-and-play)
2) Allows host mobility without hassles.
Cons:
1) Not scalable (Flooding based learning does not scale for more than 1000 hosts and also the MAC table becomes huge because each switch has to know how to divert traffic to all hosts and MAC addresses don't aggregate). We can limit broadcasts by using VLANs but they are limited (4094).
2) Spanning trees limits the available bandwidth by removing links to avoid forwarding loops.
IP
Pros:
1) Allows ECMP forwarding (limited to layer 3 networks currently). More efficient use of available bandwidth.
2) IP addresses are aggregatable and hence scalable.
Cons:
1) Difficult to configure and manage (router config, DHCP server config --> error prone)
2) Host mobility is an issue. Live Migration is needed for fault tolerance and to achieve high host utilization.
Ethernet + IP
Group Ethernet LANs via IP (run OSPF among IP routers). Layer 3 routers allow for ECMP routing and provide scalability.
Cons:
Subnetting limits host mobility to within a single LAN (subnet). Scalability becomes an issue as tenants grow. Subnetting wastes IP addresses and increases configuration overhead both of routers and DHCP servers.
Problem statement
We want ease and flexibility of Ethernet and the scalability and performance of IP while using inexpensive commodity hardware (using proprietary hardware is harder to deploy and loses the advantage of economies of scale) and should work with arbitrary topologies.
PAST relies solely on destination MAC and VLAN tags to forward the packets. So, it can use the larger MAC tables (SRAM) instead of TCAMs (higher area and power per entry than SRAM).
The paper provides a good overview of Trident switch chip and a useful table on table sizes of some of the available commercial 10Gbps switches:
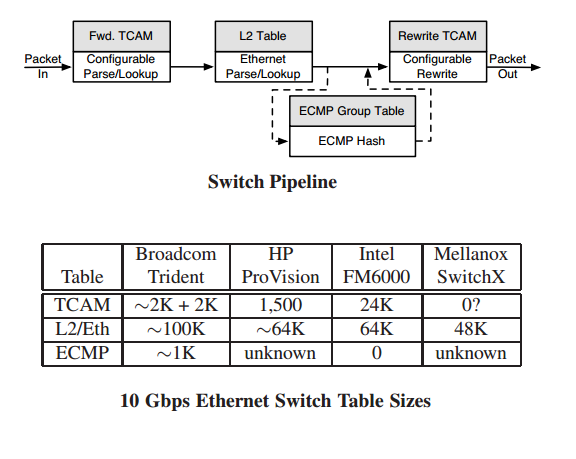
IntelFM6000 support 64K IPv4 routes as well.
Lack of information about switch internals makes it difficult for networking researchers to consider constraints of real hardware. This paper fills this gap (for Trident switch chip).
L2 table performs an exact match lookup on VLAN ID and dest MAC address. This table is much larger compared to TCAM tables. Output of the table is either an output port or a group.
TCAMs can wildcard match on most packet header fields. Rewrite TCAM supports output actions that modify packet headers. Forwarding TCAM is used to choose an output port or group. Trident can support 1K ECMP groups each with maximum 4 outport ports in the ECMP Group Table.
Switches contain a control plane processor that is responsible for programming the switch chip, listening to controller messages and participating in control plane protocols like spanning tree, OSPF etc.
IBM RackSwitch G8264 has unique capability to install Openflow rules that exact match on only dest MAC and VLAN ID in L2 table. The switch can install 700-1600 rules/s and each rule installation takes 2-12ms. Each time a packet matches no rule it is sent to the controller. The limit on this feature is 200 packets/s. Therefore reactive forwarding will not provide acceptable performance.
Given the small size of TCAMs any routing mechanism that requires the flexibility of a TCAM must aggregate routes. The paper argues that given the large size of L2 tables we can fit one entry per routable address in every switch. I don't believe this argument at all. Portland started out with the same argument and basically said that lets bring the benefits of aggregation to MAC addresses. But by doing so you again limit host placement (and in Portland's case topology also). To get around this, Layer 2 and 3 schemes make use of indirection to separate location and application addresses which leads to familiar set of inefficiencies.
SPAIN and TRILL are not able to exploit the advantages of multiple paths in topologies like Fat-Tree, Jellyfish because STP constructs a single tree to forward packets along to avoid forwarding loops.
TRILL runs IS-IS to build shortest path routes between switches but it uses broadcast for address resolution, limiting its scalability.
Multipath routing and Valiant load balancing are used to fully exploit available bandwidth in a network.
If there are multiple shortest paths between two hosts we can use ECMP to increase path diversity, avoid hotspots and flow collisions. But ECMP is applicable in architectures which find shortest path like IP routing and TRILL (IS-IS).
VLB forwards traffic minimally to a random switch after which the traffic follows minimal path to its destination.
Core idea
Many possible spanning trees can be built for an address if the topologies have high path diversity. If we make individual per-address trees as disjoint as possible we can improve aggregate network utilization.
Baseline: Destination-rooted shortest path trees.
Build a BFS spanning tree for every address in the network. This spanning tree is rooted at the destination host, so provides minimum hop-count path from any point in the network to that destination. No links are ever disabled in the topology. Every switch forwards the traffic to the host via the path calculated using STP. Forward and reverse paths can be asymmetric (since STP is calculated for each host).
Three variants
PAST-R
Pick a uniformly random next hop in BFS. Intuitively we are spreading the traffic across all the links since each destination will have a random spanning tree.
PAST-W
Use weighted randomization in BFS: Weigh the next hop selection by considering how many children next hop-switch has.
Above two variants are similar to ECMP. Unlike ECMP which enables load balancing at per-flow PAST enables load balancing on per-destination granularity.
This is similar to VLB and achieves high performance under adversarial workloads. Select a random intermediate switch i and use it as the root for the BFS spanning tree for each host h. The switches along the path in the tree from h to i are then updated to route traffic towards h and not i, making h the sink of the tree.
Evaluations found no significant difference between PAST-R and PAST-W. NM-PAST performs better than ECMP and VLB.
Implementation
PAST uses the Openflow controller-dumb switch architecture. All switches forward the ARP messages to the controller. The controller sends back ARP replies. Ditto for DHCP. Switches run LLDP, so the controller knows the entire topology. PAST is topology independent
What happens when?
1) A host joins/migrates: Migrated host sends a gratuitous ARP which is forwarded to controller. The controller calculates the new tree for the host and updates the rules on the switches.
2) A link/switch fails: All hell breaks loose. We need to recompute all affected trees (if the switch is in the core layer this can be very costly). Biggest drawback of the paper. The paper says the algorithm can compute trees for all hosts in a network with 8,000 hosts in 300ms and 100,000 hosts in 40 seconds. Installation of a single rule on the switch takes 12ms. They say it takes up to a minute for them to recover from a single failure.
Drawbacks
1) The authors say their switch does not need special hardware but they depend on using the IBM G8264 switches which is the only switch that currently supports installing Openflow rules in the Ethernet forwarding tables.
2) Installing a recomputed tree can lead to routing loops. This can be prevented by removing rules corresponding to that tree from the switches first and then use barrier command to make sure they are removed before installing new tree rules. Wastes time.
3) PAST requires one Ethernet table entry per routable address, so the scalability of the architecture is limited to the Ethernet table size (around 100K max). The paper hopes that PAST will scale well in future networks because it uses SRAM-based Ethernet tables.
SPAIN another paper similar to PAST requires a switch to store all possible (VLAN, destination MAC) pairs hence limiting the scalability of these approaches. The paper says that the switches resort to flooding in case of table overflows which is not acceptable in a big data center.
No comments:
Post a Comment